
俗语说:人以群分,物以类聚。朋友之间基本上是臭味相投的,再进一步延伸,朋友的朋友也应该能成为新的朋友。那么进行推荐服务的方法可以这样来实现:先找出用户已经关注朋友的名单,再进一步找出每个朋友所关注的对象,再根据频数作为推荐的权重。下面我们用Twitter为例用R语言来实现这种思路。
先从笔者的推号入手(@xccds),提取了100名关注对象的信息。然后对每个关注对象再提取他的100名关注对象信息,合并后制成频数表,剔除笔者已经关注过的对象。排序后保留频数最高的前五名,绘制条形图以显示最后的推荐结果。查了一下这几位的资料,感觉还比较靠谱,值得follow。各位经常上推的朋友也不妨一试。
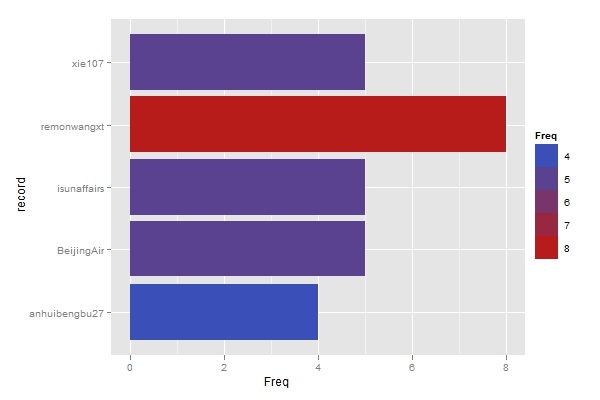
注:由于Twitter API有限制,所以并未完全获得所有一万条信息,上图是根据大约两千条信息绘制的。
R代码如下:
rm(list=ls())
library(twitteR) #加载包
myid <- getUser('xccds') #获取用户信息
#取得100名关注对象的用户名
myfo <- twListToDF(myid$getFriends(n=100))$screenName
ffo <-list()
record <- character()
for (i in 1:100){
user <- getUser((myfo[i])) #获取关注对象的信息
#取得关注对象的关注对象
ffo <- twListToDF(user$getFriends(n=100))$screenName
record <- c(record ,as.character(ffo))
}
# 生成频数表
table.record <- table(record)
# 从表格转化为数据框
data = as.data.frame(table.record,stringsAsFactors=F)
# 将已经关注的对象从中删除
data <- data[data$record%in%setdiff(record,myfo),]
# 选择频数最高的五人
data <- data[order(data$Freq,decreasing=T)[1:5],]
# 加载包并绘制条形图
library(ggplot2)
p <- ggplot(data,aes(record,Freq))
p + geom_bar(aes(fill=Freq))+coord_flip()
感谢博主的慷慨分享
回复删除你可以分7天来挖掘twitter数据。 7 x 1,500 = 10,500 条信息了。
回复删除good idea
删除